A particular aspect that I’ve been interested in about Haskell is its rich
parsing combinators:
“Parser Combinators: Parsing for Haskell Beginners”
Building a parser up out of composable functions that act as “parser plug-ins”
is far superior to RegEx. You have the freedom to name things clearly, and
to re-use facilities from the language that you already know (e.g. looping
and subfunctions). And just because you’re using abstractions doesn’t mean the
runtime will get slower…a “function reference” doesn’t get unconditionally
turned into a “function call”.
One idea in particular captured my imagination: that having your parse rules
expressed mathematically would allow efficient parsing of near-infinite
length streams. e.g. the amount of input that needed to be held onto in
memory at one time would be determined by whether you had used rules that
required backtracking or not…and you’d get the right amount of memory use
that your rules needed.
Researching seemed to suggest that neither Parsec nor Megaparsec would do
incremental parsing. 😢 The go-to answer for those looking for incremental
parsing was Attoparsec, which could use “IO Streams” as input. But it had a
disclaimer regarding memory use:
Note: incremental input does not imply that attoparsec will release portions
of its internal state for garbage collection as it proceeds. Its internal
representation is equivalent to a single ByteString: if you feed incremental
input to a parser, it will require memory proportional to the amount of input
you supply. (This is necessary to support arbitrary backtracking.)
Despite that, I decided to pick my first “real” Haskell programming task as
decoding an arbitrarily long stream of IP addresses with Attoparsec. I’d
see for myself that a rule that just skipped values would not be able to
release memory, and be in a position to explore why it couldn’t do better.
A Function for Faking A Stream
The first sample I found on “infinite” parse was for processing Redis
logs. It used parseWith, and passed some initial data and a “fill”
function that could add more–whenever the parser needed more data it would
call the fill. Parsing was then performed as several individual calls into
Attoparsec to get one value at a time…with the residual data (if any)
returned to use in the next call.
Instead, I decided to try Attoparsec’s integration with System.IO.Streams.
I wanted to write code that was stylized to work with files or a network, but
without actually generating gigantic files or making a mock network server.
So I was drawn to the promising capability of letting you simulate a stream
by means of a function:
makeInputStream :: IO (Maybe a) -> IO (InputStream a)
Creates an InputStream from a value-producing action.
(makeInputStream m) calls the action m each time you request a value from
the InputStream. The given action is extended with the default pushback
mechanism (see System.IO.Streams.Internal).
I could tell by the IO signatures that this was going to be a trial-by-fire.
The function I’d be giving makeInputStream would have to be “evil”. It
needed some kind of memory…otherwise it would have to always return data,
or never return data.
The function didn’t take any parameters–and Haskell has no globals. So making
it would have to be a two-step process: have one function that creates the
state, and then fabricate a new parameterless function that knows to use that
state. Here’s that written in JavaScript, but stylized so that it corresponds
line-for-line to how I wrote it in Haskell:
// makeCharEmitter :: returns function that returns a character or null
function makeCharEmitter() {
let ref = { n: 1 }
return function () { emit(ref) }
}
// emit :: takes integer reference -> returns a character or null
function emit(ref) {
let i = ref.n
ref.n = ref.n + 1
switch (i) {
case 1: return 'A'
case 2: return 'B'
default: return null
}
}
> e = makeCharEmitter()
> e()
<- "A"
> e()
<- "B"
> e()
<- null
I did something “weird” by wrapping the integer in an object, but that was so
it could be passed around and updated by reference. Haskell lets you make
this kind of variable in the IO monad with IORef.
So now here’s the Haskell version. To my fellow noobs: Do NOT let the code
scare you!! Be brave and compare to the JavaScript.
import Data.IORef
makeCharEmitter :: IO (IO (Maybe Char)) -- // makeCharEmitter :: ...
makeCharEmitter = do -- function makeCharEmitter() {
ref <- newIORef 1 -- ref = { n: 1 }
return (emit ref) -- return function () { emit(ref) }
where
emit :: IORef Int -> IO (Maybe Char) -- // emit :: ...
emit ref = -- function emit(ref) {
do
i <- readIORef ref -- let i = ref.n
modifyIORef ref (+ 1) -- ref.n = refn + 1
case i of
1 -> return (Just 'A') -- return 'A'
2 -> return (Just 'B') -- return 'B'
_ -> return Nothing -- return null
main :: IO ()
main = do
e <- makeCharEmitter -- e = makeCharEmitter()
print =<< e -- console.log(e()) // 2-line version:
print =<< e -- // c <- e
print =<< e -- // print c
This outputs what I intended…mutable state for the win!
Just 'A'
Just 'B'
Nothing
It took me the better part of an evening to figure out how to write that in
Haskell (which was actually less time than I thought it would take). Having
red wavy underlines showing you errors in VS Code as you type really makes a
difference while learning. So if you haven’t got that configured, do yourself
a favor and push through on getting it set up.
Type errors cue you to things like the difference between i <- readIORef ref
and i = readIORef ref. Because = just establishes a synonym for things,
while <- effectively “peels off” the IO Monad…so that functionally pure
primitives like case can work with the contained values. And even if
something is weird–like an IO (IO (...)) signature–the type checking
leads you to code that may “just work”, even if you don’t understand why!
Parsing a Stream of IP Addresses
I found code to steal for parsing an IP address with Attoparsec at School
of Haskell. But that just used a fixed string (processed with parseOnly).
I wanted to use parseFromStream…which doesn’t have much in the way of
examples on the Internet.
The only stream type that Attoparsec would appear to have predefined for
supporting is a stream of ByteString. This surprised me, because “formally
speaking” I’d think the correct type would be as a stream of individual bytes
(e.g. Word8). But I guess that for efficiency, read operations are geared
toward handing back chunks of data at a time.
Since I’d already arranged my streaming code to make one-character at a time,
I used Data.ByteString.singleton to form a stream that spits out ByteStrings
that are one byte long. It cycles through three fixed IP addresses, for
however many times you ask when the emitting function is created (here just
tests 5):
{-# LANGUAGE OverloadedStrings #-} -- so "192.168.1.0" acts as ByteString
module Main where
import Data.Attoparsec.ByteString.Char8
import System.IO.Streams.Attoparsec.ByteString
import Data.Word
import Data.ByteString as B
import Data.IORef
import System.IO.Streams (Generator, InputStream, OutputStream)
import qualified System.IO.Streams as Streams
data IPState = IPState { ipIndex :: Int, charIndex :: Int }
ipString :: Int -> B.ByteString
ipString i =
case i `mod` 3 of
0 -> "192.168.1.0"
1 -> "8.8.8.8"
2 -> "255.255.255.0"
updateState :: IPState -> IPState
updateState s =
let
ipIndex' = ipIndex s
charIndex' = charIndex s
str = ipString ipIndex'
len = B.length str
in
if charIndex' == len then
IPState { ipIndex = ipIndex' + 1, charIndex = 0 }
else
s { charIndex = charIndex' + 1 }
charToWord8 :: Char -> Word8
charToWord8 = toEnum . fromEnum -- https://stackoverflow.com/a/54504966
makeBytesEmitter :: Int -> IO (IO (Maybe B.ByteString))
makeBytesEmitter numIpAddresses = do
ref <- newIORef (IPState 0 0)
return (emit numIpAddresses ref)
where
emit :: Int -> IORef IPState -> IO (Maybe B.ByteString)
emit numIpAddresses ref =
do
state <- readIORef ref
let
ipIndex' = ipIndex state
charIndex' = charIndex state
ipString' = ipString ipIndex'
len = B.length ipString'
if ipIndex' == numIpAddresses then
return Nothing
else do
modifyIORef ref (updateState)
let
byte = if charIndex' == len then
charToWord8 '\n'
else
B.index ipString' charIndex'
return (Just (B.singleton byte))
data IP = IP Word8 Word8 Word8 Word8 deriving Show
parseIP :: Parser IP
parseIP = do
d1 <- decimal
char '.'
d2 <- decimal
char '.'
d3 <- decimal
char '.'
d4 <- decimal
char '\n'
return $ IP d1 d2 d3 d4
main :: IO ()
main = do
s <- Streams.makeInputStream =<< (makeBytesEmitter 5)
print =<< parseFromStream parseIP s
print =<< parseFromStream parseIP s
print =<< parseFromStream parseIP s
print =<< parseFromStream parseIP s
print =<< parseFromStream parseIP s
done <- Streams.atEOF s
if done then
print "All five IP addresses successfully consumed"
else
print "Stream had residual input"
I didn’t spend time making the code particularly elegant (not that I could
even if I wanted to, at this point). But it does what I was aiming for:
IP 192 168 1 0
IP 8 8 8 8
IP 255 255 255 0
IP 192 168 1 0
IP 8 8 8 8
"All five IP addresses successfully consumed"
Memory Usage When Taken To “Infinity”?
The hope I had with this exercise was that I could show that there wasn’t
state accumulating somewhere. To test this, I switched to a looping structure
for main:
main :: IO ()
main = do
s <- Streams.makeInputStream =<< (makeBytesEmitter 10200304)
let
looper = do
print =<< parseFromStream parseIP s
looper
looper
Ten million is close enough to infinity for my purposes. :-) I ran this for a
long while so that IP addresses flew by, and watched the numbers in top:
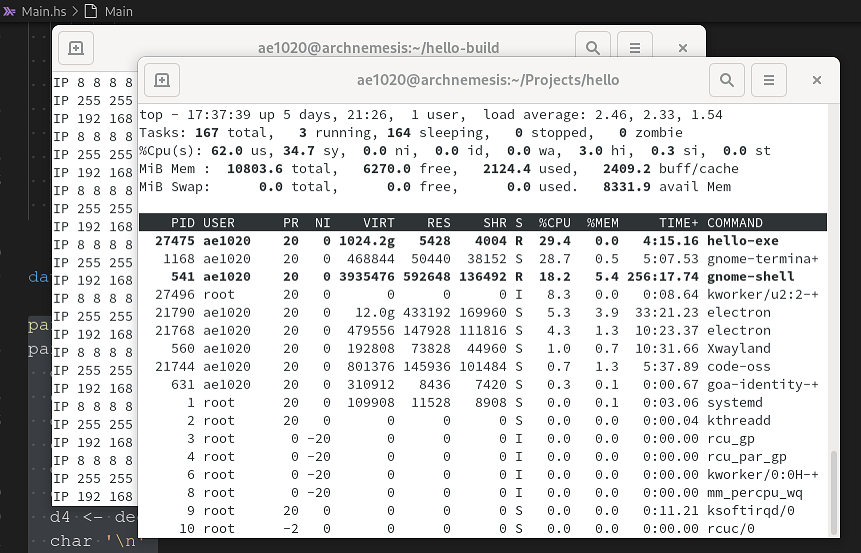
I was somewhat taken aback by the VIRT showing up as 1,024,200 gigabytes,
e.g. a terabyte. But this has nothing to do with Attoparsec in particular.
It turns out that as of GHC 8.0, all 64-bit Linux Haskell programs request
that much virtual memory ahead of time at startup. (It’s apparently becoming
a common practice these days…e.g. Go does it too).
However, the RES (resident) memory use stays completely flat at 5,428k. This
demonstrates that the buffering abstraction layer used over the stream really
is forgetting unnecessary data as it goes along.
Could a Composed Parser Know What to Forget?
Now I wanted to test if a single composed rule that did not need backtrack
released memory. The Attoparsec documentation said it WOULD require memory
proportional to the input, but I held onto hope that meant it COULD need
that much…if the rules required it.
The most obvious combinator that wouldn’t need backtrack would be skipMany.
So I decided to skip all the IP addresses and see if that made it to EOF:
main :: IO ()
main = do
s <- Streams.makeInputStream =<< (makeBytesEmitter 10200304)
print =<< parseFromStream (skipMany parseIP) s
done <- Streams.atEOF s
if done then
print "10200304 IP addresses successfully consumed"
else
print "Stream had residual input"
Bad news is, this just keeps raising the amount of memory used. As I
watched top tick along, RES kept growing. Sometimes it grew in sudden jumps,
it leapt from 199172 to 302550 in one moment. Ultimately it finished at
around 314MB. Back-of-the-envelope calculations suggest the input is 115MB
or so, which means there was a bit of bloat.
(What is likely is that the technique the IO Streams are using to present a
buffer on top of the one-byte-at-a time emissions are creating some multiplier
when interacting with Attoparsec. I presumed such a thing would happen, but
it wasn’t that relevant as I was just wondering if the growth was infinite
or not.)
I’d picked the System.IO.Streams because it was supported out of the box by
Attoparsec. I figured that with a name like System it might be blessed
and supported broadly…like things in the std:: namespace of C++ for
<iostreams>. That’s apparently not what “System” means, as it’s actually
an umbrella for “things that interact with the operating system”.
It seemed not many people discussed these streams. Instead there was talk
about “Conduit”, “Pipes”, “Streaming” etc. There was an existing adapter to
use Conduit with Attoparsec, so I decided to give that a shot–following the
pattern of sourceHandle in Conduit…with the same messy methodology:
import Conduit (
ConduitT, bracketP, liftIO, mapM_C, runConduitRes, (.|), yield
)
import Data.Conduit.Attoparsec (conduitParser)
import Control.Monad.Trans.Resource
{- ...VARIOUS CODE FROM BEFORE (parseIP, updateState, etc)... -}
sourceFake :: MonadResource m
=> Int
-> ConduitT i B.ByteString m ()
sourceFake numIpAddresses = do
ref <- liftIO $ newIORef (IPState 0 0)
loop ref
where
loop ref = do
state <- liftIO $ readIORef ref
let
ipIndex' = ipIndex state
charIndex' = charIndex state
ipString' = ipString ipIndex'
len = B.length ipString'
if (ipIndex' == numIpAddresses) then
return ()
else do
liftIO (modifyIORef ref (updateState))
let
byte = if charIndex' == len then
charToWord8 '\n'
else
B.index ipString' charIndex'
yield (B.singleton byte)
loop ref
main :: IO ()
main = do
runConduitRes
$ sourceFake 10200304
.| conduitParser parseIP
.| mapM_C (liftIO . print)
This ran in constant memory like when parseStream used the rule for one
parseIP at a time. So when you make a “conduit” out of parseIP it will
seemingly yield one value at a time when used with mapM_C.
Conclusion
Haskell’s parsing abilities are certainly good, but my investigation of this
topic led me to two things that disappointed me somewhat:
-
The most powerful modern parsers (e.g. Megaparsec) don’t seem to be designed
to be able to suspend their state to ask for more input. This would
presumably preclude them working with streaming input of any sort (?) which
seems rather limiting.
-
Attoparsec holds onto all of its input until the application of a given
top-level parse has finished. While I showed that it releases memory between
those top-level calls, it can’t deduce conditions where backtracking won’t
be needed from how the rules were combined.
I know too little about Monads to reason out whether what I want is possible.
Can a parser that is framed monadically “see into” the composition to know what
the earliest point of backtracking could be? It may be that there’s no way
to do it without describing the parse with some custom declarative structure,
which might make one ask what writing it in Haskell actually buys.
(UPDATE: I started a thread on the Haskell Discourse on this topic.)
Despite having my hopes dashed a bit on what how “magical” incrementality
would be, this exploration went pretty well. I multiplied my Haskell knowledge
quite a bit…pushing me along on my be less ignorant in 2020 initiative.
:-) Hopefully I’ll get to the point of being able to say smart Haskell things
soon.
